HabitPulse. Part 1
Introduction
You know the saying, “If all you have is a hammer, everything looks like a nail?” That’s kinda me with technology. Sometimes, whether you genuinely need it or just for the fun of it, you pick tools not strictly because they’re the perfect fit, but hey – why not build something cool, right?
Motivation
Everyone has a quest to cultivate good habits – exercising, reading, or maybe just drinking enough water. But tracking these? Ugh, it can be a chore. Despite the myriad of apps available, most feel like piloting a spaceship when all you want is to ride a bike. Plus, as a backend engineer, any UI I’d whip up wouldn’t come close to the elegance of Telegram. So, building a Telegram bot for this? Kind of a no-brainer.
High-Level Design
The bot’s journey with a user begins when they specify which habits they want to track. Once these habits are set, every log entry revolves around selecting a predefined habit category and inputting a value. For instance, choose ‘Pushups’ and enter ‘50’. This simplicity ensures that the logging experience is hassle-free.
All these entries are remembered, aggregated, and displayed back to users in several forms. We’re talking engaging graphs that show the progression of their habits, daily summaries, and monthly round-ups. And, for those who are into stats, there’s even the option to see a dynamic analysis of their consistency and progress over time.
Interactions
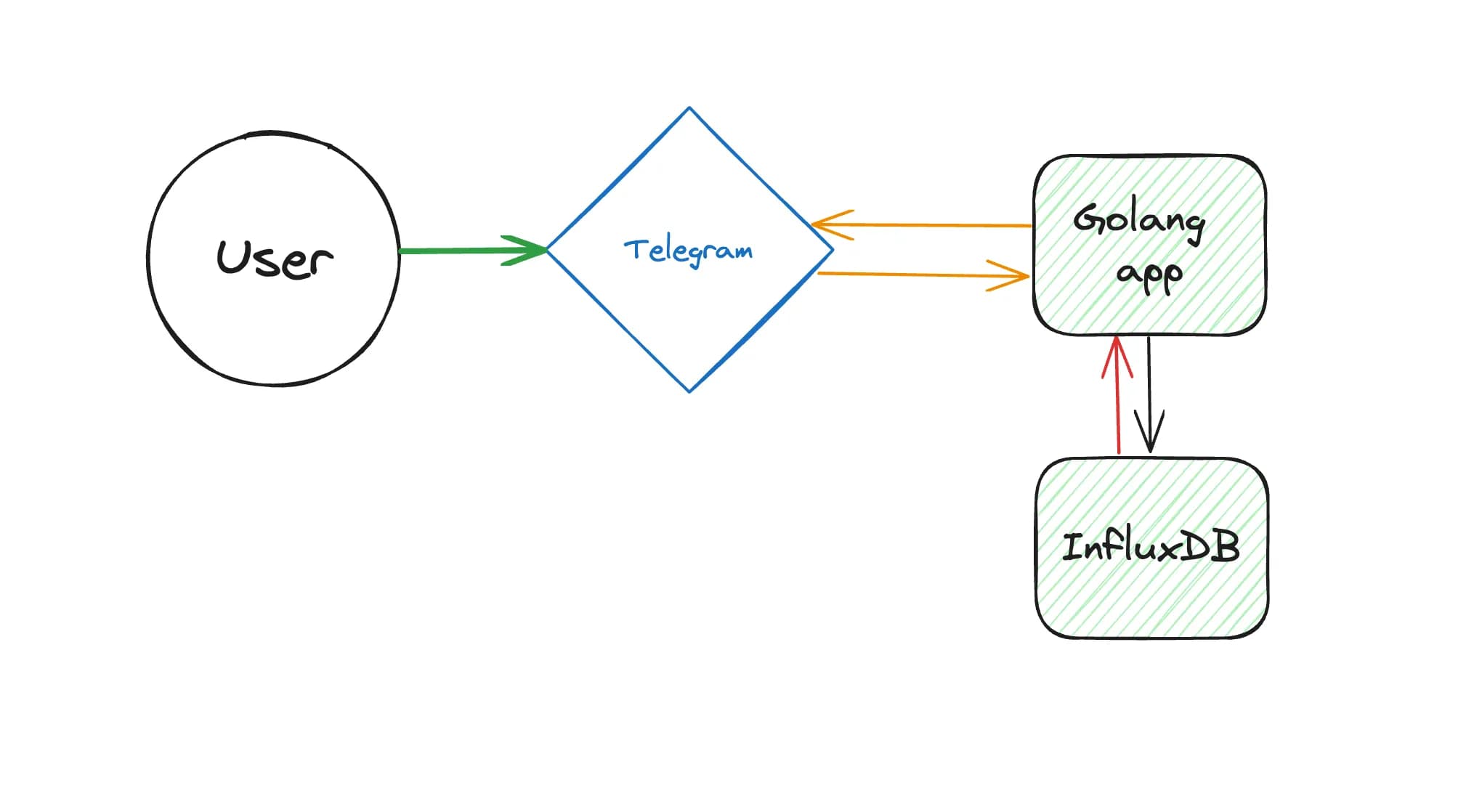
- User interaction with the Telegram Bot.
- Bot sending/retrieving data to/from the Go service.
- Go service interacting with InfluxDB to store/retrieve data.
Technical Decisions
Why Golang?
Why did I pick Go? Well:
- It’s in my toolbelt. I know Go.
- It’s kinda like that reliable truck; might not be fancy, but gets the job done. Fast, efficient, and deploys without tears – because, binaries!
- And the cherry on top? Go’s got this treasure trove of libraries, ensuring I don’t reinvent the wheel and get things done in a snap.
Why InfluxDB?
Could’ve gone the SQLite route or something similar. But a Time Series Database (TSDB) like InfluxDB? That’s jazzing things up! Our habit data, tied to timestamps and values, mirrors metrics. And InfluxDB’s geared to handle such data. So, it’s like fitting a square peg in a square hole – snug and satisfying.
Anatomy of an InfluxDB Record and Our Use Case
Understanding InfluxDB’s record structure is crucial for our habit-tracker. Here’s a breakdown:
InfluxDB Record Structure:
- Measurement: Like a table in relational databases.
- Tags: Indexed key-value pairs. Speeds up queries.
- Fields: Actual data values with a timestamp. Not indexed.
- Timestamp: When the data point was added.
Mapping to Our Habit-Tracking Bot:
- Measurement: The
UserIDensures individual user data stays separate. - Tags:
HabitType(likepushupsorreading) to categorize habits. - Fields: Habit data, such as 50 pushups on a day.
- Timestamp: When the user logs the habit.
Alternative Structure:
We could’ve treated every habit type (like pushups or reading) as a separate measurement. However, this approach would lead to an explosion of measurements, making it harder to manage and query.
Why this choice?
By using the UserID as the measurement, we keep each user’s data distinct. It simplifies our queries, making them user-centric. While scalability might become an issue with a massive user base, it’s a bridge we’ll cross when we get there. The current structure aligns with our objective of keeping things uncomplicated.
Next Steps
Consider this a teaser. In upcoming articles, we’ll deep-dive into the actual bot-building adventure – complete with code snippets and more. So, stick around!